A Not-so-Complex Guide to Complexity Theory
April 5th, 2023Preface
This post is a byproduct of an introduction to complexity theory presentation I gave to some of my physicist colleagues in quantum information. Quantum information is an extremely multidisciplinary field, which results in many people having knowledge gaps in some foundational concepts. After all, we cannot expect degrees in math, physics, computer science, and many engineering fields for one person to start a career in quantum information. All of this is to say that this post is written for the scientist from a different field that wants to dip their toes in computer science, in order to understand papers or talks that include these concepts to a greater extent. As a consequence, this post will go deeper into the details of complexity theory than your average layman-oriented introduction. I do still encourage the layman to read this post, because although mathematical languages can be a hard-to-grasp topic, the prerequisites to understand this post do not go beyond knowing the difference between a polynomial and an exponential equation.Asymptotic Notation
In order to be able to quantify the amount of resources an algorithm requires, we must first learn asymptotic notation, which is the standard in computer science. Asymptotic notation describes a function in terms of its behavior as the input approaches infinity. For example let’s start by defining one of the most common notations, the Big O notation. Say you have a function f(x) which you are comparing to another function g(x). Now let’s assume that we ignore anything that happens to both functions before some arbitrary point \(x_0\), but after this point, f(x) is always below g(x). See the figure below for an example
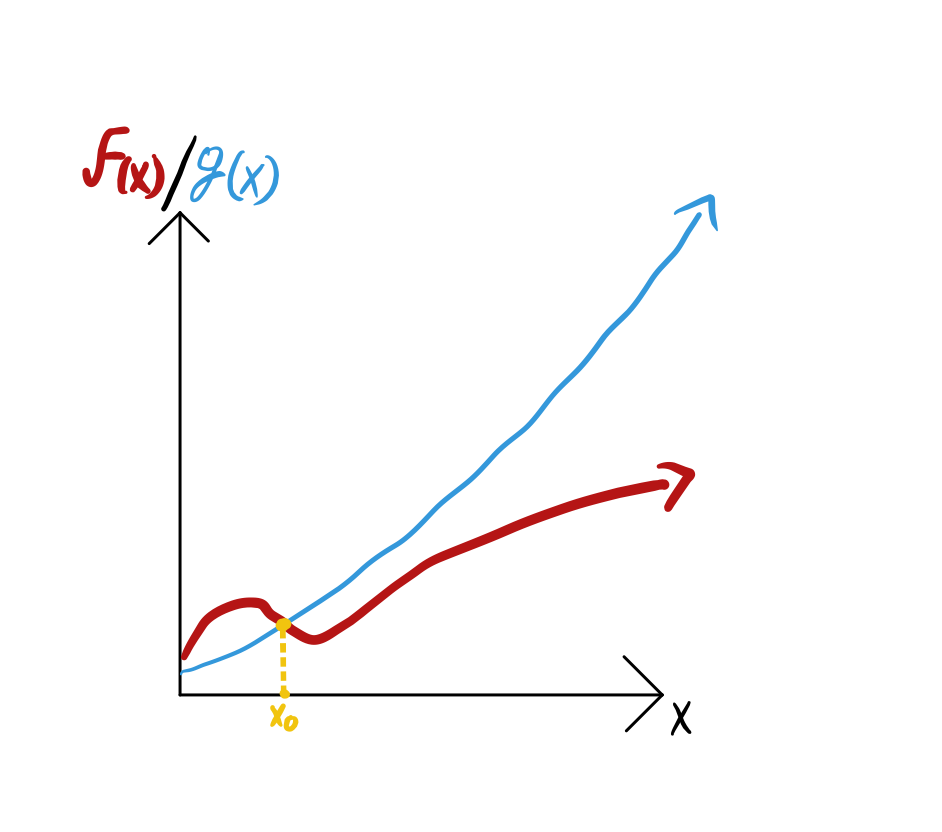
If this condition is met, we say that f(x) is Big O of g(x). To be more specific
This measure sets an upper bound for our function, it is bounded above by g(x). As I mentioned before, the goal of this formalism is to be transferred to a measure of computing resources. The function f(x) represents the amount of resources needed by our algorithm after taking x bits as input. For example, a common resource that is examined is time[1]. One could replicate the graph from the figure above, where the y-axis represents the number of seconds an algorithm took to finish, and the x-axis the number of bits given to the algorithm as input. Because we always want to minimize the resources used, a higher value in the graph is always considered a worse value. Due to this, the sentence “f(x) cannot be higher than g(x)” is often written as “f(x) cannot be worse than g(x)”. In fact, the Big O of a function is usually called the “worst-case complexity”.
Similarly, there is another notation used called Big Omega which is the opposite of Big O. A function f(x) is said to be Big Omega of g(x) if after some point \(x_0\) it is always above g(x)
This g(x) is then considered the best-case complexity of f(x). Now you can quantify resources like a theoretical computer scientist!
Classical Complexity Theory
To go deeper into complexity theory, we must go over a little bit of set theory. More specifically, languages! Buckle up.
A language is a set of words built from a defined alphabet. In computer science we usually choose our alphabet to be {0,1}. Therefore, a language can be defined as a collection of bitstrings. For example; one could define a language L as the language where every string must end with a 0
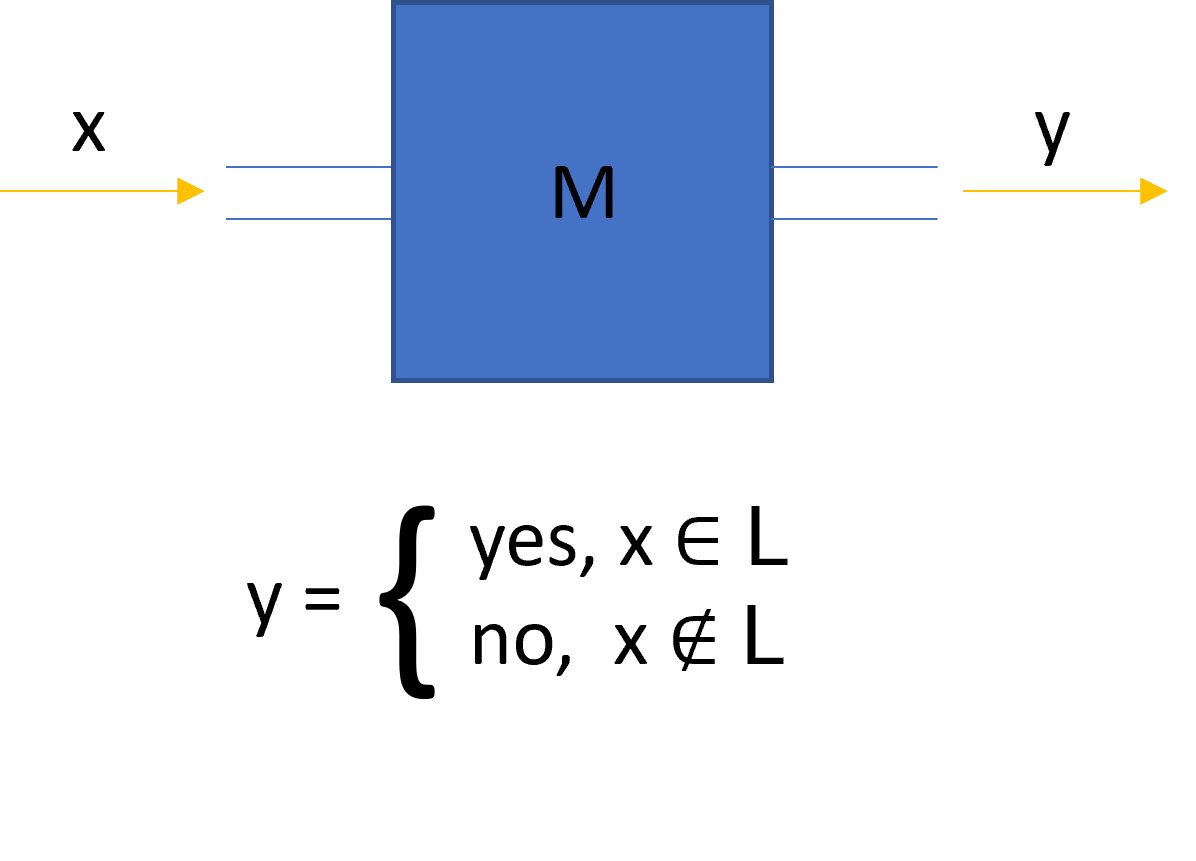
So we have languages, and the elements that make up that language, are words. Imagine we now build an algorithm M that when you give it a bitstring, it outputs “yes”, if the input is a word that belongs in L, and outputs “no” if the input is a word that does not belong in L. Then we say that our algorithm M “decides” the language L. [1]
Now we can build some sort of zoo[2] of languages where we separate them depending on the different resources needed. For example, “P” is defined as the class of languages that require a polynomial amount of time to be decided. In other words, their Big O corresponds to a g(x) which is a polynomial[3] Similarly, the class “EXP” is defined as all languages that can be decided in an exponential amount of time. Now let’s take a moment to think about the relationship between these two classes. If there is a language L which is shown to be in P, then by definition there exists an algorithm M that decides L in polynomial time. We can then build a new algorithm M’ such that: receive input x, send it into the algorithm that we know solves it in polynomial time, M, and then stall an exponential amount of time [4]. Finally, output whatever came out of M. This proves that any language that is in P, is also in EXP. Proofs that do not depend on any constraints of the language represent properties of the entire class because it works for all languages in the class. In this case, we proved that the class P is contained inside EXP! This is the heart of complexity theory.
P vs. NP (+ an example of a language!)
Although not the main topic I want to discuss in this post, one cannot introduce complexity theory without mentioning the famous millennial problem of P vs. NP. We already defined P above, so now let me tell you what NP is. At a high level, a language L belongs in NP if we can verify a word “x” belongs in L in polynomial time with help from another bitstring “c”, called the certificate. We are guaranteed to be able to recognize words in the language through the existence of an accompanying certificate. Pay attention to the slight differences with the class P. The first one is that the algorithm is given an extra piece of information asides from the word, a certificate. The second one, maybe a bit more subtle, is that the case where the word does not belong in L is not specified. This means that given a word that does not belong in the language, our algorithm could run forever and it would still be considered to be in NP. If it helps, at a high-level NP is usually described as "languages that can be verified efficiently".

So far this post has been very abstract, so let’s come down from our theory cloud a little bit and talk about an example, satisfiability problems (also called SAT). Imagine there are n boolean variables \(x_1, x_2, …, x_n\) and we now make groups out of them, relating them with the \(\lor\) (OR) operator [5], for example:
Each one of these groups is called a “clause”. If there exists an assignment for each variable, such that every clause evaluates to 1, then we say the problem is satisfiable. The example above is satisfiable, take the instance \(x_1 = 1\), \(x_2 = 1\), \(x_3 = 0\), \(x_4 = 0\).
How do we describe this problem in terms of everything we have learned so far? Well, problems can be described as languages. In this case, the language is SAT, and the words in SAT correspond to instances that are satisfiable. If we continue to use the example above, \(x_1 \lor x_3 \) and \(x_2 \lor ¬x_1 \lor x_4\) is defined as a word, and because we know that it is satisfiable (there is a solution), then we say this word belongs in SAT.
At the time of writing this post, there is no known efficient algorithm to recognize if a SAT instance is satisfiable. If we consider a brute force algorithm where we just try every possible assignment of the n variables and compute the clauses, that corresponds to at least \(2^n\) attempts, which is exponential! Finally, let’s see why SAT is in NP. If I give you a word that belongs in SAT, that is, a SAT problem that does have a solution, you would have to (in the worst case scenario) try every possible assignment to find the solution and confirm that it is in SAT. But, if I also gave you the satisfying assignment, you could plug in the solution and verify that it works. In the case of the SAT, the “certificate” is just the solution to the SAT problem, thus with these two inputs, one can identify words in SAT efficiently. This is the definition of NP, so we can conclude that SAT belongs in NP.
The Millenium Prize problem of P vs. NP consists of proving that P = NP or P != NP. The set P is contained in NP, which means all problems that can be solved efficiently, can also be verified efficiently. Let’s consider these two scenarios separately.
P != NP would mean that NP is strictly bigger than P. This can be shown by proving that one single problem cannot be solved efficiently, but given a certificate, it can be verified efficiently. This problem would then live in the shaded region shown below

P = NP would mean that every problem that can be verified efficiently, can also be solved polynomially. Which implies the shaded region above is non-existent. This would have dramatic consequences, and our world would be quite different. For example, not only would you be able to claim one million dollars for solving the P vs. NP problem, but an extra 5 million dollars because then you could solve all the other ones in polynomial time! Because of this, even though no one has solved the P vs. NP problem, they are assumed not to be equal. It is common to state as a conjecture that P != NP. If you are interested in learning more about this conjecture, I encourage you to read this paper
Further Reading: Common Asymptotic Behavior Criticism
Classifying resources in terms of their asymptotic behavior, allows us to compare them as the problem sizes get bigger. It does not say anything about how many resources a problem will need, but only how the resources needed will change as we go towards bigger problems. Considering in practice we use computers for problems too big to do by hand, this quantifier tends to give us a very good way to compare algorithms. Here are two common arguments against this practice:
- We don't live in asymptopia!: In the real world, problem sizes do not go to infinity. We should be practical and not use infinities to classify finite-size problems. What if the input sizes that I care about are below the \(x_0\) under which the behavior of the resources is unknown?
- Classifying a problem as "efficient" cannot be done only based on the shape of the function. What if a problem is solvable in polynomial time, but the polynomial is n to the power of 50 000? Or what if a problem takes exponential time, but the exponential is 1.000 000 01 to the power of n [7]
Notice that these two problems are two sides of the same coin: infinite theoretical framework vs. finite world. The answer to this is simple: it has worked great so far. In practice, we do not tend to have algorithms that stay below \(x_0\) for an input size that represents a useful problem and is too big to do by hand. As for the second point, I'll leave this quote by S. Aaronson bringing up some examples: "If cases like that regularly arose in practice, then it would’ve turned out that we were using the wrong abstraction. But so far, it seems like we’re using the right abstraction. Of the big problems solvable in polynomial time – matching, linear programming, primality testing, etc. – most of them really do have practical algorithms. And of the big problems that we think take exponential time – theorem-proving, circuit minimization, etc. – most of them really don’t have practical algorithms."[7]
[1] Other examples of resources to be modeled by f(x) are; memory/space, T-gates, magic states, and black-box queries. This last one is typically called "Query-Complexity Theory"
[2] The word algorithm is very vague in terms of mathematics. If you were to read any of the concepts related to this post in a more formal context, such as a textbook, they will use “Turing Machine” instead of "algorithm". In order to avoid extending this post further by explaining what a Turing Machine is, I decided to omit this. The ideas presented in this post will remain correct if the reader has a basic understanding of what an algorithm is. If you want to be really careful about these definitions, I recommend you learn what a Turing machine is, and replace every instance of “algorithm” with it!
[3]If you ever see someone say that a problem can be solved “efficiently” they mean in polynomial time.
[4] This is a reference to the complexity zoo. A website created to keep track of all the complexity classes described in the literature
[5] If stalling is too hand-wavy for you, you can imagine putting a for loop after using subroutine M, where the range of the loop is exponential in x. The body of the loop can be your favorite arithmetic operation or anything else that does not affect the output
[6] This operator returns 1 if at least one of the variables is 1, read this for more details
[7] Scott Aaronson. (2013) Quantum Computing Since Democritus. Page 54. Cambridge University Press.